On Policy vs. Off Policy
Table of Contents
Basic Prerequisite Knowledge
- States and Actions: Signified by . Imagine yourself trying to walk through a field to get somewhere. There are two things you need to do to avoid being a vegetable. One, have some knowledge of what’s going on around you (ex. location of my goal and what’s 3 steps in front, behind, left, and right of me). That’s your state. Two, you need to actually do stuff to get there (ex. move forward, back, left, or right). That’s your action.
- Trajectory: A trajectory is simply the path you take to try to get to your goal. I also call this a series of “state-action pairs”, which simply means your trajectory develops as each time you decide you want to take an action, you evaluate your state and then take an action (See, it’s so easy a caveman could do it. Rest in peace old GEICO commercials).
- Policy: The thing our RL agent uses to choose what actions to take
- Q-value (): a.k.a. an “action value”. This is a value represents “how good” an action is from a given state.
- Q-learning and SARSA: No need to understand the details of these. Q-learning is an off-policy method to update a system’s Q-values and SARSA is an on-policy method to do the same. After optimization, the Q-values should converge to stationary values that allow for an agents to optimally traverse an environment to accomplish the RL agent’s goal.
On Policy vs. Off Policy
| On Policy | Off Policy | |
|---|---|---|
| Definition | Policy being used to explore the environment is the same as the policy being optimized | Policy being used to explore the environment is independent of the policy being optimized |
| Examples | SARSA N-Step Actor-Critic |
Q-Learning Evolution Strategies |
Breaking it Down
The key here is the difference between what I call an RL agent’s “action policy” and an “update policy” . The action policy is the method that our agent uses to choose its actions and explore. This is also termed the “target policy ()” because our objective is to improve this policy and eventually use it for evaluation. The update policy (exemplified by the in the Q-Learning update) is the method by which we choose the state action pairs we use to update and optimize our action policy.
For on-policy methods, we use the action policy to both do updates and choose actions. For off-policy methods our action policy has to be different than the update policy. So, the way we explore is independent of the way we optimize.
Let’s see several examples of action policies
Note: These methods ensure that if enough trials are done, each action will be tried an infinite number of times, thus ensuring optimal actions are discovered.
- -greedy
- With high probability the action with the highest estimated (greedy) reward is chosen. With small probability , an action is selected uniformly at random.
- softmax
- Sample from the action space , some weighted by its action-value estimate. This is a good approach to take where the worst actions are very unfavorable.
Let’s see and example of an update policy
Note: These are usually algorithm-specific
- Q-Learning update function
- By updating Q-values using , the update policy learns using the best (greedy) possible state-action trajectory path even when actual exploration via the action policy is more random and not always greedy.
Let’s focus on the one difference between the update functions in both Q-Learning and SARSA: the max operator in front of the Q-value that estimates our expected future reward, in other words, the “update policy” for Q-Learning.

For on-policy SARSA, the Q-value () we use for updates is parameterized by sampling a state action pair from our action policy (e.g. softmax). Intuitively, this means we follow state action pairs along the known trajectory that our policy will take and update their Q-values, , along the way. You can see that the name “on-policy” is appropriate as we are making updates by directly following our action policy.
For off-policy Q-Learning, we have an additional update policy (Q-learning update function) which is independent of our action policy. While we still sample an action from our action policy to physically move our agent, the state action pairs that parameterize the are chosen by a completely different update policy. If we maintain the same action policy for our on-policy SARSA example, the action policy is sampled, while the update policy for Q-Learning is greedy, making it off-policy.
Therefore, if this update policy is different than our action policy, then we are not following the action policy for our updates, giving us an “off-policy” method. If our action policy and update policies are one and the same, then we have an “on-policy method.”
Visual Example
Sutton and Barto have a good example of how these two methods differ in their book “Reinforcement Learning: An Introduction” Book (Search: Example 6.6: Cliff Walking). Imagine you have a robot trying to find a safe path from state S to goal G in a simple grid world. However, the shortest path between the two is blocked by a cliff with a large negative penalty (-100). All other spaces have a small negative reward (-1) to incentivize moving to the goal as quickly as possible as moving around aimlessly would also incur more and more penalty.
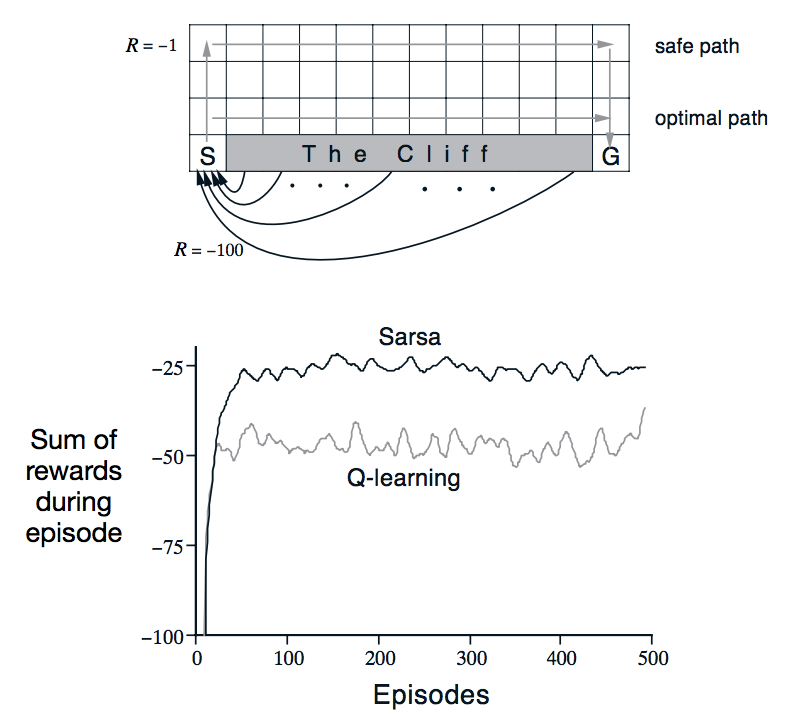
Using one of our active policies from the list above (i.e. epsilon greedy), notice that there is an optimal path (the edge of the cliff) and a safe path (the far side away from the cliff). Both accomplish the task, but because there is a small chance that we will randomly sample an action, moving along the edge of the cliff is risky, as we may fall into the cliff by choosing a random action.
Because on-policy SARSA uses the non-deterministic action policy in its updates, its learning accounts for this randomness, encouraging the safe path to the goal. Meanwhile, off-poilcy Q-Learning optimizes using the optimal update policy, so it learns the risky optimal path. We can see from the graph that the off-policy method’s average online performance is worse than that of SARSA, however if were gradually reduced, then both methods would asymptotically converge to the optimal policy, so epislon greedy action policies usually reduce over time.
Because off-policy algorithms such as Q-Learning have some non-deterministic exploration path (i.e. -greedy, -soft, softmax)
So which is better?
This answer, like with most RL techniques, is that it depends. Given sufficient training under any -soft policy (policy that has a non-zero chance of randomly exploring), both algorithms will converge to a close approximation of the optimal action-value function for an arbitrary target policy. However, there are different benefits to each method.
The trade off can be abstracted to optimality (off-policy) vs. safety (on-policy). If taking the optimal path is extremely important and entering risky states is not too damaging (i.e. trying to get the high score in an Atari game), off-policy methods should have a higher best case online performance. However, if those risky states are of high penalty (i.e. self driving vehicle crashes), on-policy methods will optimize towards the safer path during online training.
Relevant Topics
- Experience Replay
- (A3C) Asynchronous Methods for Seep Reinforcement Learning
Sources
- Stack Overflow explanation of On vs Off Policy
- Simple Explanation of On-Policy Q-Learning and Off-Policy SARSA
- Action policies: -greedy, -soft, softmax
- Q-Learning and SARSA Algorithm pseudo code:
- Sutton and Barto’s “Reinforcement Learning: An Introduction” Book (Search: Example 6.6: Cliff Walking)