[Paper] DeepMimic: Example-Guided Deep Reinforcement Learning of Physics-Based Character Skills
Table of Contents
- Credit
- Summary of the Abstract
- Major Problems (and Their Solutions) During Training
- Neural Network Architectures
- Algorithm
- Two Term Reward
- Enabling A Multi-Skilled Agent
- Other Results
- Relevant Topics
- Sources
Credit
This blog post is simply a summary and overview of the paper listed below. My own opinions may be reflected here as well. For reference to the authors’ own work please see the references at the very bottom of this page.
Paper: DeepMimic: Example-Guided Deep Reinforcement Learning of Physics-Based Character Skills
Credit for all motivating work goes to the authors of the DeepMimic paper listed below.
- XUE BIN PENG, University of California, Berkeley
- PIETER ABBEEL, University of California, Berkeley
- SERGEY LEVINE, University of California, Berkeley
- MICHIEL VAN DE PANNE, University of British Columbia
All gifs were spliced from the following videos:
SIGGRAPH 2018: DeepMimic paper (main video)
SIGGRAPH 2018: DeepMimic paper (supplementary video)
Summary of the Abstract
The goal of this paper is to use well-known RL methods to train a simulated figure to copy a motion clip while also accomplishing the task shown by the clip (e.g. perform a back flip, throw a ball, etc.). The authors combine a motion-imitation objective, such as “copy the joint rotations of the human” with a task objective “throw the ball into a target” and train an RL agent to accomplish these objectives in simulation. They also explore methods to integrate multiple clips into the learning process and develop multi-skilled agents that can perform diverse skills in a logical sequence (e.g. roll when you need to recover from falling). They demonstrated these result with using various characters (human, Atlas robot, bipedal dinosaur, dragon) and a large variety of skills, including locomotion, acrobatics, and martial arts and achieved extremely realistic performance by the simulated RL agent.
Major Problems (and Their Solutions) During Training
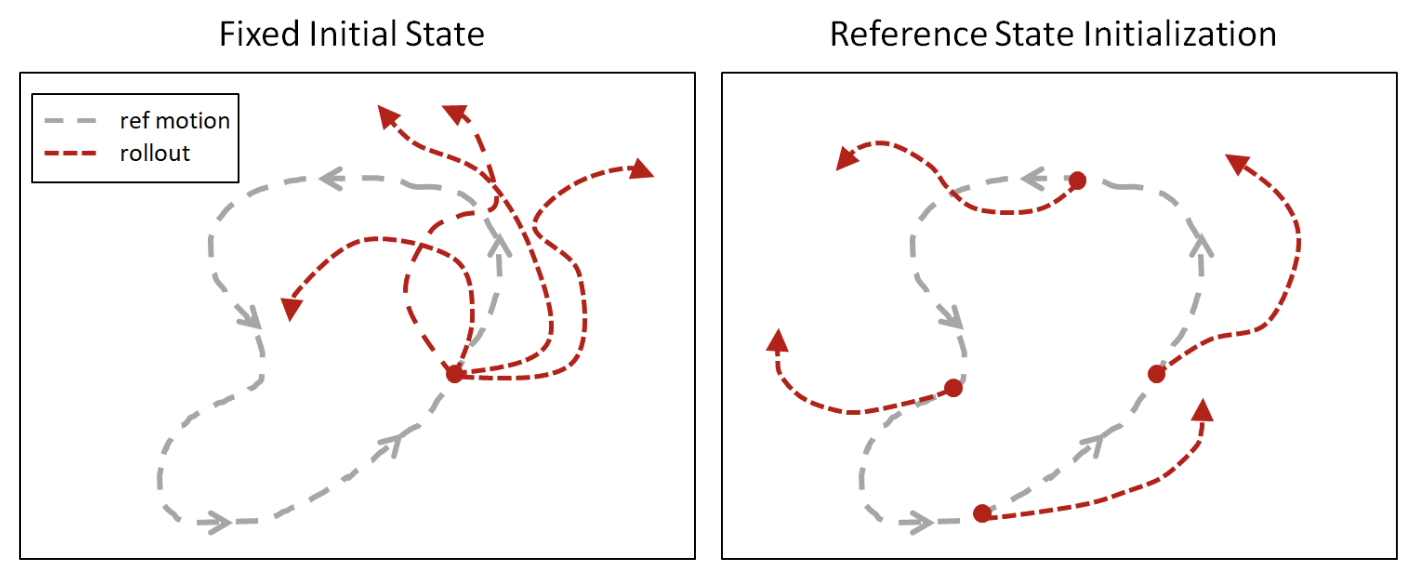
Problem #1: Fixed Initial State in Sequential Learning
The authors discovered that if they always started the agent from the same state (position and orientation) for each simulation, learning took much longer and even converged to suboptimal situations where high-value states weren’t even visited (e.g. the top part of a back flip). This issue was the result of two difficult roadblocks in RL techniques.
- Progress cannot be made on later actions before mastering earlier ones
- Until a high reward state is visited, the policy will never know about it.
This means that, when attempting a flip, we have a chicken and egg problem.
Chicken: For an agent to discover that a full mid-air rotation is highly rewarded, it must first perform a viable jumping motion
Egg: For an agent to be motivated to do such a jump, it needs to know that the full mid-air rotation is a high-reward state

Solution: Reference State Initialization
To solve the chicken and egg issue, we simply initialize each episode with a randomly sampled state from the reference motion. If we do this, our agent can learn from high reward states before even learning how to reach them.
Note: This works because the agent will learn to converge to the initially sampled reference state. This is important because if we don’t converge to the initially sampled state, then learning from that state could be much less useful.
Problem #2: Fixed Period Termination for Cyclic Tasks
By fixing the number of timesteps that a simulation takes before it automatically terminates and by having no failure condition that zeros out the reward for the remainder of a training cycle, the resulting data will be dominated by agents attempting to recover from failures instead of focusing on globally optimizing the task. This is the case because failures happen more often than successes and are hard to recover from.
Here is an example where an agent falls on the floor and continuous attempting a flip in that state instead of accomplishing the flip.

Solution: Early Termination
To solve this, we must simply stop any training episode that reaches some termination criteria (i.e. the torso hits the ground). After this time, the agent is left with zero reward for the remainder of the episode (eliminating the effect of any data from further actions).
This simple solution biases the data distribution in favor of samples that are actually relevant to the global task.
As we see here, the combination of these two solutions removes limiters that would prevent our agents from succeeding.

Left: RSI+ET. Middle: No RSI. Right: No ET
Neural Network Architectures
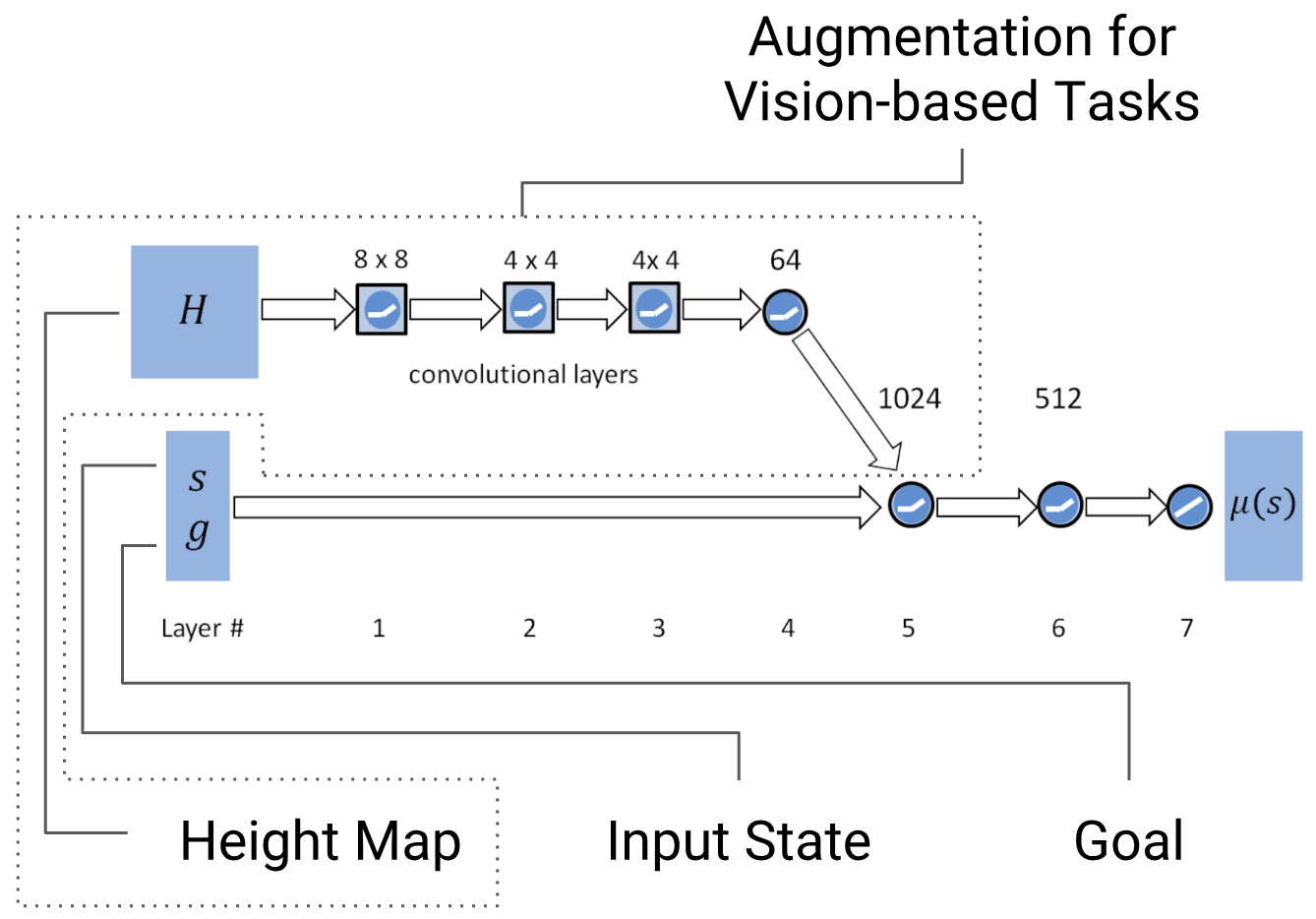
Policy Network
The authors used a neural network to map state $s$ and goal $g$ to a Gaussian action distribution, represented by a layer of linear units (one for each action dimension (joint)). They would use the resulting Gaussian means $\mu(s)$ and a fixed diagonal covariance matrix (hyperparameter) to sample actions for their training.
Note: This network is augmented with a height map for vision-based tasks.
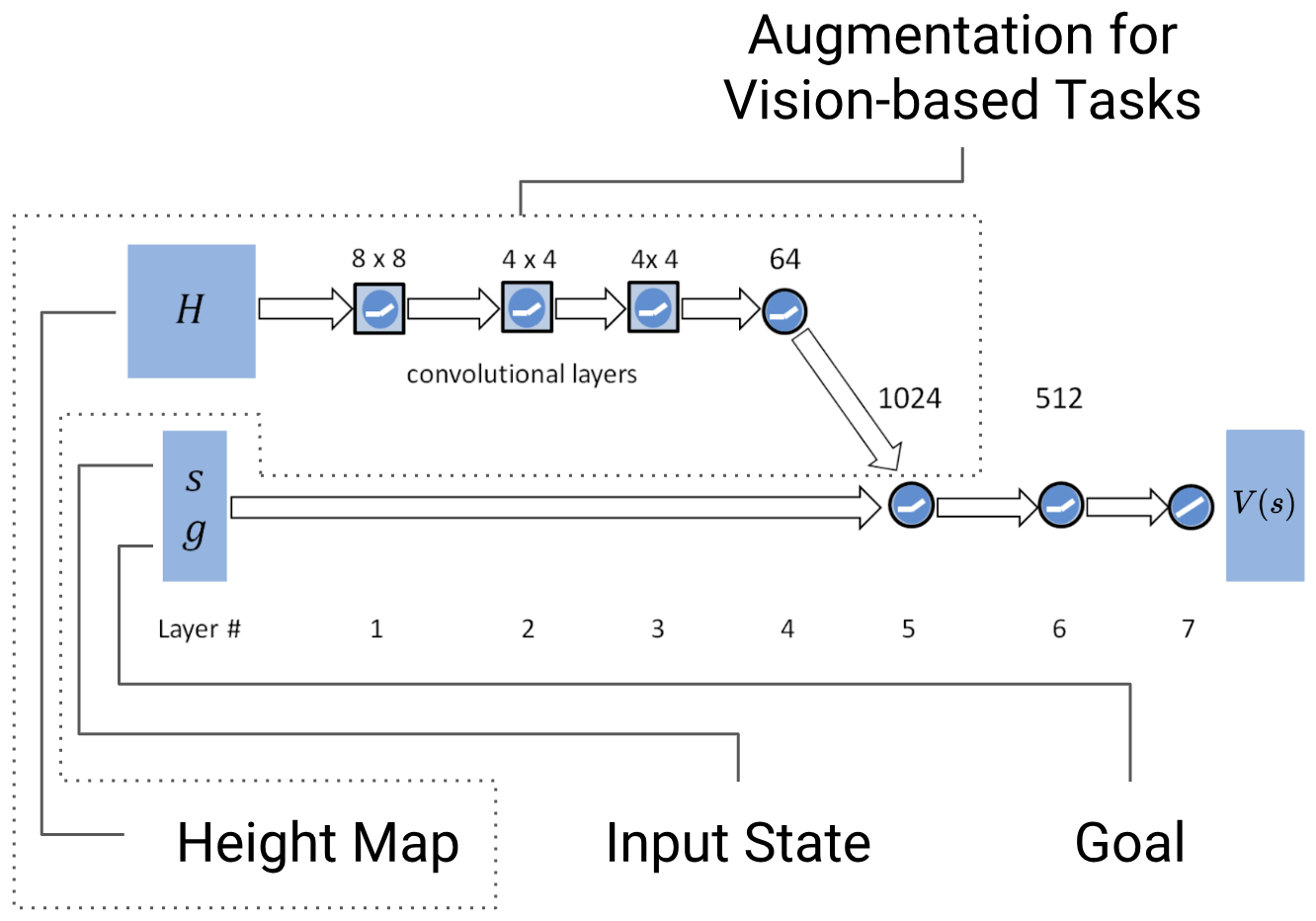
Value Network
Another neural network was used to map state $s$ and goal $g$ to a single estimated value $V(s)$, which would represent how “good” that given state was. This network is designed almost identically to the policy network, but output layer consists of a single linear unit.
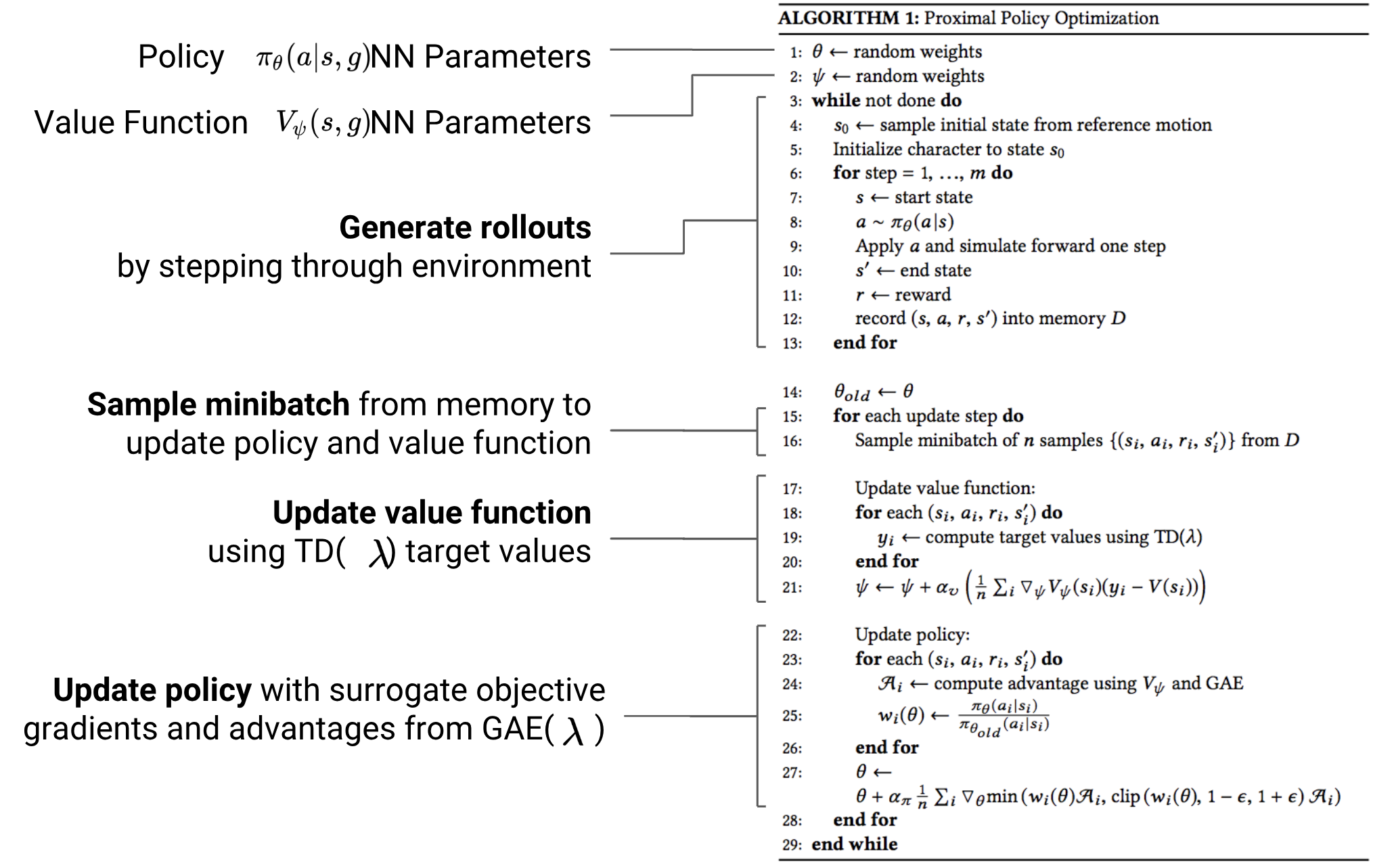
Algorithm
(PPO) Proximal Policy Optimization
The authors used PPO because it does well to mitigate high variance issues with policy gradients and avoids the difficulties of enforcing hard KL divergence constraints as in TRPO.
Temporal Difference (TD) Target Value Estimator
TBD
Generalize Advantage Estimate (GAE)
TBD
Surrogate Clip Loss
TBD
Two Term Reward
The combined imitation objective and task objective used for training is defined as such:
- Reward weights $\omega^I$ and $\omega^G$ are tunable hyperparameters
- $r_t^I$ is the imitation reward
- $r_t^G$ is the task reward
Imitation Reward
The imitation reward is further broken down into 4 components:
Where the following definitions and objectives are given:
| $r_t^p$ | Pose Reward | Match joint orientations |
| $r_t^v$ | Velocity Reward | Match joint velocities |
| $r_t^e$ | End-Effector Reward | Match positions of hands and feet |
| $r_t^c$ | Center of Mass Reward | Match center of mass positions |
Pose Reward
By including this in the imitation objective, the agent will minimize the difference between the joint orientation quaternions of the reference motion and the simulated character.
Variable and Operation definitions:
| $\hat{q}_t^j$ | Orientation of the reference agent’s $j$-th joint at timestep $t$ (represented as a quaternion) |
| $q_t^j$ | Orientation of the simulated agent’s $j$-th joint at timestep $t$ (represented as a quaternion) |
| Gives the absolute difference between 2 quaternions in terms of scalar rotation about the quaternion axis (in radians) |
Velocity Reward
This causes the agent to minimize the difference between local joint velocities of the reference character and the simulated character.
Variable and Operation definitions:
| $\hat{\dot{q}}_t^j$ | Target velocity of $j$-th reference joint (calculated by finite difference using data) |
| $\dot{q}_t^j$ | Angular velocity of the $j$-th joint in simulation |
End-Effector Reward
This allows the agent to minimize the difference between the end-effector positions of the reference motion and the simulated character.
Variable and Operation definitions:
| $\hat{p}_t^e$ | 3D world position (in meters) of the $e$-th reference end-effector |
| $p_t^e$ | 3D world position (in meters) of the $e$-th end-effector in simulation |
Center of Mass Reward
Finally, the agent will also minimize the difference between the center of mass point of the reference and simulated characters.
Variable and Operation definitions:
| $\hat{p}_t^c$ | Reference character’s center of mass |
| $p_t^c$ | Simulated character’s center of mass |
Task Rewards (Various Types)
Note: For all of these, if a vision system is needed (i.e. terrain has obstacles, bumps, etc.), the policy and value networks are augmented with a height map as noted in the network architecture section.
Target Heading (Walking in a Specified Direction)
This task reward penalizes the agent from moving slower than the desired speed along the target direction, but does not penalize it for exceeding the requested speed.
Variable and Operation definitions:
| $v^*$ | Reference agent’s velocity |
| Projection of the simulated agent’s velocity along the proper direction . This will be less than if the agent is moving slower than along . |
Terrain Traversal
This goal is constructed exactly the same way as the target heading goal, but the target is in a fixed direction. The authors also used a “progressive learning” approach where they first trained a fully connected network to imitate reference motions on a flat terrain, then augmented the networks with height map inputs and convolutional layers and trained the agent on irregular environments.

Strike / Throw
The objective here is for the agent to strike a randomly placed spherical target using a specific link (e.g. arm, leg, etc.) or projectile.
Variable and Operation definitions:
| $p_t^{tar}$ | 3D world location of target |
| $p_t^e$ | 3D world location of link or projectile used to hit target |
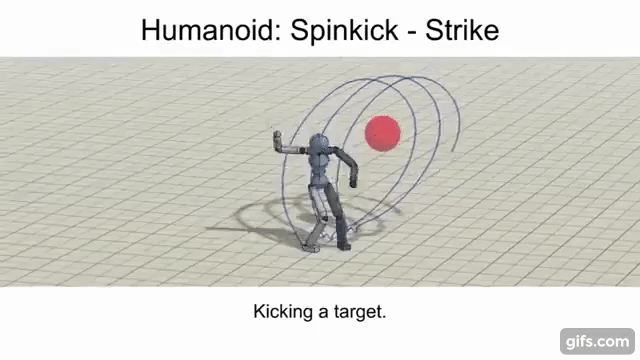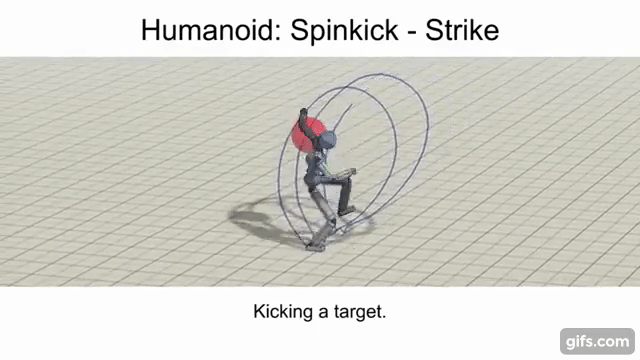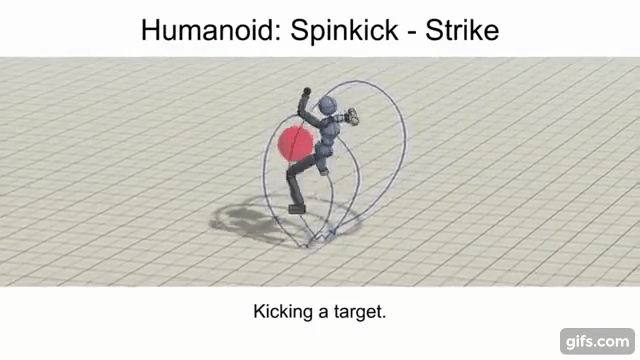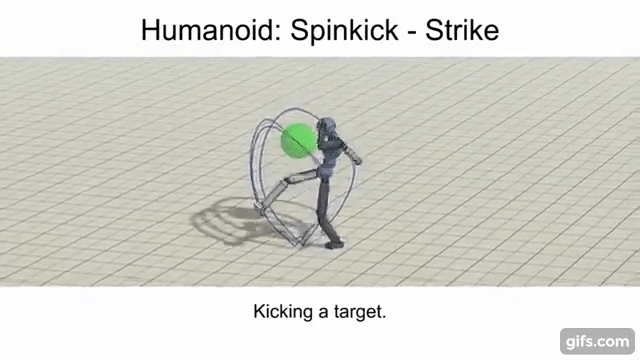

Enabling A Multi-Skilled Agent
Multi-Clip Reward
By using an imitation reward that can choose which reference state motion to copy between multiple clips, this gives the policy the flexibility to select and optimize on the most appropriate clip in a given situation (i.e. The clip that yields the highest total reward $r_t$ remember that this includes the task reward)
Variable and Operation definitions:
| $r_t^j$ | Imitation reward for clip $j$ of $k$ |


Skill Selector
To allow a human operator to be able to manually instruct the agent to perform various tasks (select a skill), we can eliminate the task reward $r_t^G$ because we no longer need it. Instead, we randomly select a clip and optimize only the imitation reward $r_t^I$ for that clip.
By randomly and uniformly sampling the reference clips during training, this enforces the policy to learn transition between all skills within the set of clips.

Composite Policy
Instead of using a single policy as we did for the single clip tasks, we can create a composite policy for a variety of different action sequences to optimize for the best outcome given any state.
As you see below, the policies with larger expected values at a given state will more likely be selected. This gives the agent the desired behavior of using the most logical action to recover from bad states. For example, if the agent is knocked down during a cartwheel by an external force, it will recover by rolling and standing up instead of continuing to cartwheel.
Variable and Operation definitions:
| $\pi^i(a \mid s)$ | Policy representing a likelihood of choosing some action $a$ given some state $s$ |
| $p^i(s)$ | Probability of selecting policy $i$ given some state $s$ |
| $V^i(s)$ | The result of the value function given some state $s$ to determine how good being in state $s$ is |
Note: The ratio seen above is also termed a Boltzmann distribution, which has roots in thermodynamics. Here, it is applied as a sort of boosting term (see: Section 7.3 of http://snasiriany.me/files/ml-book.pdf) to cause policies that will perform better in the given state to have higher probabilities of being chosen.

Other Results
When comparing the DeepMimic results to the results of other RL based humanoid control tasks, we see a massive improvement in realism. By using reference motions, the authors have used a semi-supervised approach to include realism into their global reward. By adding robustness to their model they could also react to adversarial physical forces and train arbitrary agents with varying sizes and shapes to perform well for all skills.
Credit: Photos and captions taken from the “More Results” section of the BAIR blog post: Toward a Virtual Stuntman by Xue Bin (Jason) Peng.


Left: DeepMimic, Right: Other RL techniques for humanoid running

All skills learned by the humanoid agent


Atlas trained to perform a spin-kick and backflip. The policies are robust to significant perturbations.

Simulated T-Rex trained to imitate artist-authored keyframes.

Simulated dragon with a 418D state space and 94D action space.
Relevant Topics
- (PPO) Proximal Policy Optimization
- Reducing Variance
Sources
- [Paper] DeepMimic: Example-Guided Deep Reinforcement Learning of Physics-Based Character Skills
- Proximal Policy Optimization Algorithms
- A Comprehensive Guide to Machine Learning
- Xue Bin (Jason) Peng: Towards a Virtual Stuntman
- SIGGRAPH 2018: DeepMimic paper (main video)